
哪里不会扫哪里!全球最强数学大模型人人可玩,阿里多模态模型加持
衡宇发自凹非寺
量子位|公众号QbitAI
现在,最强数学大模型,人人都可上手玩了!
一觉醒来,阿里千问大模型团队发布了Qwen2-Math的Demo,抱抱脸在线可玩
。
惊喜的是,如果嫌输入数学公式比较麻烦,可以把想问的题截图or扫描,上传即可解题。
整得挺方便。
试玩界面上明确写着,“这个试玩界面的OCR功能,由阿里千问大模型团队Qwen2-VL提供支持;数学推理能力,由Qwen2-Math支持。”
阿里高级算法专家林俊旸也在推特评论区进一步解释:
目前,Qwen2-VL和Qwen2-Math还是各自负责一部分。
但不久的将来,我们会把多模态能力和数学推理能力结合到一个模型
上哟。
不少网友对这种交互模式挺买账:
歪瑞古德!用图像来上传,然后等大模型解决问题,喜欢!
那么,最强数学大模型Qwen2-Math,上手效果怎么样?
效果怎么样?这就玩一把
是时候让Qwen2-Math过五关斩六将了!
先来几道比较简单的计算题开开胃。
提前说明,两位体验过程中,Qwen2-Math不是一边算一边显示的,而是计算完毕后直接显示过程和结果。
(而且应该是越来越多人开始玩了,结果生成时间逐渐拉长)
第一题:
“计算AxA A=240”中,A的值。
Qwen2-Math给出了正确答案,A=14或A=-16。
第二题:
给定a的值,计算等式的结果。
Qwen2-Math计算出,答案是0,也是对的。
第三题:
(A 3)(A 4)(A 5)=120,求A的值。
Bingo!答案是1。
OK,热身结束,给Qwen2-Math点难度看看。
那就来一道已经是(数学)大模型测评的标配:
9.9和9.11哪个更大?
Qwen2-Math自信回答:
9.9比9.11更大!
那就再上点难度!
扔给它一道截至目前,只有GPT-4o答对过的题:
一个外星人来到地球后等可能选择以下四件事中的一件完成:
1、自我毁灭;
2、分裂成两个外星人;
3、分裂成三个外星人;
4、什么都不做。
此后每天,每个外星人均会做一次选择,且彼此之间相互独立。
求地球上最终没有外星人的概率。
这道题,Qwen2-Math花费了约30秒左右的时间,给出答案:1。
很遗憾,答案是错误的,正确答案是√2减1。
我们在各大平台的评论区逛了一下,除了计算错误以外,还有另一种可能导致答案不正确——
那就是Qwen2-VL在识别题目的时候,本身就出错了。
错在第一步,这样的话大模型得出的肯定就不是正确答案。
同时,林俊旸还在网友的评论区表示:
咱们Qwen2-Math目前还不能做几何题
用中文提问也可以
这次的主角Qwen2-Math,基于通义千问开源大语言模型Qwen2研发,由阿里千问大模型团队在十天前发布。
它专用于数学解题,并且能够解决竞赛级试题。
Qwen2-Math总共有三个参数量的版本:
72B,7B和1.5B。
在Qwen2-Math-72B的基础之上,千问团队还微调出了Instruct版本。
这也是Qwen2-Math的旗舰模型,它是一个数学专用的奖励模型,将奖励信号与正误判断信号结合作为学习标签,哪里不会扫哪里!全球最强数学大模型人人可玩,阿里多模态模型加持再通过拒绝采样构建监督微调(SFT)数据,最后在SFT模型基础上使用GRPO方法优化。
Qwen2-Math-72B-Instruct以84%的准确率处理了代数、几何、计数与概率、数论等多种数学问题。
并且一经发布就在数学大模型中“登基”,在MATH数据集上比GPT-4o多得了7分,按比例算高出了9.6%。
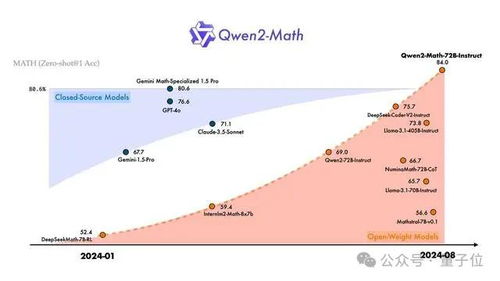
直接超越开源Llama3.1-405B以及闭源的GPT-4o、Claude3.5等。
截至发稿,抱抱脸上Qwen2-Math-72B-Instruct的下载量超过了13.2k。
而且有个最新发现:
虽然团队声称Qwen2-Math目前还是主要针对英文场景,但如果拿中文题目去问它,Qwen2-Math还是能进行解答的
只不过是用英文回答你罢了。
据了解,Qwen2-Math的中英双语版本将会在之后推出
参考链接:
[1]https://huggingface.co/spaces/Qwen/Qwen2-Math-Demo
[2]https://x.com/Alibaba_Qwen/status/1825559009497317406
[3]https://x.com/JustinLin610/status/1825559557411860649










评论