
比性价比高百倍!推出新推理服务,号称全球最快
智东西(公众号:zhidxcom)
编译|Vendii
编辑|漠影
智东西8月28日消息,AI芯片独角兽CerebrasSystems于8月27日宣布推出AI推理服务CerebrasInference,号称“全球最快”。该服务已经在云端上线。
据官网介绍,该推理服务在保证精度的同时,速度比英伟达的服务快20倍;其处理器内存带宽是英伟达的7000倍,而价格仅为GPU的1/5,性价比提高了100倍。CerebrasInference还提供多个服务层次,包括免费、开发者和企业级,满足从小规模开发到大规模企业部署的不同需求。
用户可直接在官网上的交互界面进行体验,也可调用API。
体验地址:https://inference.cerebras.ai/
CerebrasSystems成立于2016年,团队由计算机架构师、计算机科学家、深度学习研究人员和各种工程师组成。该公司以其创新的晶圆级芯片(WaferScaleEngine,WSE)而闻名,这些芯片专为AI计算而设计,具有巨大的尺寸和性能。
这家芯片独角兽曾经得到多个知名投资者的支持,其中包括OpenAI联合创始人SamAltman、AMD前CTOFredWeber等。截至2021年11月,该公司完成了2.5亿美元的F轮融资,估值达到40亿美元。
一、性价比远超英伟达:速度快20倍,价格仅为1/5AI推理指的是在训练好一个AI模型之后,使用这个模型对新的数据进行预测或决策的过程。AI推理的性能和效率对于实时应用至关重要,例如自动驾驶汽车、实时翻译或在线客服聊天机器人等。CerebrasInference(以下称作“Cerebras推理服务”)便是一个专注于AI推理的服务,以支持这些对实时性要求极高的应用场景。
Cerebras推理服务由CerebrasCS-3系统及其第三代晶圆级芯片(WSE-3)提供支持。WSE-3于3月发布,比性价比高百倍!推出新推理服务,号称全球最快基于2021年推出的WSE-2芯片进行了改进。WSE-3内存带宽高达21PB/s,是英伟达H100GPU的7000倍。这种超高的内存带宽可以大幅减少数据传输时间,提高模型推理的速度和效率。
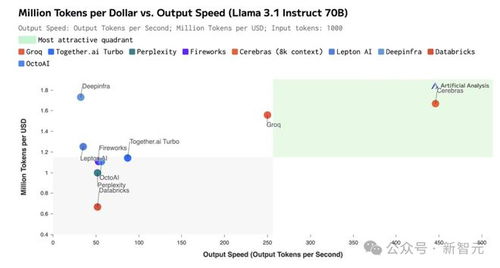
据官网介绍,Cerebras推理服务针对Llama3.18B模型每秒提供1800个tokens,每百万tokens的价格为10美分;针对Llama3.170B模型每秒提供450个tokens,每百万tokens的价格为60美分。速度比基于英伟达GPU的超大规模云解决方案快20倍。
▲Cerebras推理服务与其他服务在Llama3.18B上的速度比较。单位:tokens/秒/用户。(图源:Cerebras官网)
▲Cerebras推理服务与其他服务在Llama3.170B上的速度比较。单位:tokens/秒/用户。(图源:Cerebras官网)
此外,Cerebras推理服务在整个推理过程中始终保持在16位精度域内,确保在提升速度的同时不会牺牲模型的精度。大语言模型质量评估公司ArtificialAnalysis的联合创始人兼CEOMicahHill-Smith谈道,他的团队已经验证了Llama3.18B和Llama3.170B模型在Cerebras推理服务上运行的质量评估结果:与Meta官方版本的原生16位精度一致。
跟据官网,该服务运行Llama3.1的速度比基于英伟达GPU的解决方案快20倍,而提供服务的芯片WSE-3价格仅为GPU的1/5,相当于AI推理工作负载的性价比提高了100倍。
“在ArtificialAnalysis的AI推理基准测试中,Cerebras推理服务已经领先。Cerebras推理服务的速度比基于GPU的解决方案快一个数量级,打破了测试的纪录。”MicahHill-Smith说,“凭借推动超高的性能速度和具有竞争力的定价,Cerebras推理服务对具有实时或高容量需求的AI应用开发者特别具有吸引力。”
二、清晰的分级访问制度,用户可免费体验Cerebras推理服务根据用户需求和使用情况,提供了分级制度,分为三个层级:
1、免费层级:这一层级为所有登录用户提供免费的API访问权限以及相对宽松的使用限制。用户可以在这个层级中体验,无需支付费用。
2、开发者层级:这一层级专为灵活的无服务器部署设计,为用户提供一个API端点。相比于市场上的大多数方案,其成本要低得多。对于Llama3.18B和Llama3.170B模型,每百万tokens的价格分别是10美分和60美分。未来,Cerebras计划持续推出对更多模型的支持。
3、企业层级:这一层级提供经过微调的模型、定制的服务级别协议和专门的支持。它适合需要持续的工作负载。企业可以通过Cerebras管理的私有云或在企业的本地部署访问Cerebras推理服务。可按需求定价。
Cerebras推理服务的这种分级制度旨在满足从小规模开发到大规模企业部署的不同需求。
三、推动多方战略合作,构建AI开发一条龙服务在推动AI开发的战略合作伙伴关系中,CerebrasSystems正与一系列行业领导者合作,共同构建AI应用的未来生态。这些公司在各自的领域内提供关键技术和服务,比如,Docker旨在利用容器化技术使AI应用部署更加便捷和一致,LangChain为语言模型应用提供快速开发框架,Weights&Biases打造了供AI开发者训练和微调模型的MLOps平台……
“LiveKit很高兴能与Cerebras合作,帮助开发者构建下一代多模态AI应用。结合Cerebras的计算能力和模型以及LiveKit的全球边缘网络,所开发的语音和视频AI应用将实现超低延迟并更接近人类特征。”LiveKit公司的CEO兼联合创始人RussellD’sa说道,该公司专注于构建和扩展语音和视频应用程序。
AI搜索引擎创企Perplexity的CTO兼联合创始人DenisYarats认为,Cerebras推理服务可以帮助AI搜索引擎在用户交互方面实现突破,从而提高用户参与度。
结语:AI计算战事升温,高效推理成焦点根据国际数据公司(IDC)的研究,AI推理芯片在2020年已经占据了中国数据中心市场的50%以上份额,并预计到2025年,这一比例将增长至60.8%。据英伟达2024财年数据中心的业绩会纪要,其公司该年度有超过40%的收入来自AI推理业务。可见,AI推理不仅在当前市场中占有相当比例,而且预计在未来几年将继续保持增长势头。
Cerebras凭借其超快的推理速度、优异的性价比和独特的硬件设计,将赋予开发者构建下一代AI应用的能力,这些应用将涉及复杂、多步骤的实时处理任务。
然而,在生态系统的成熟度、模型支持的广泛性以及市场认知度方面,英伟达仍然占据优势。相比于Cerebra,英伟达拥有更大的用户群体和更丰富的开发者工具和支持。此外,虽然Cerebras支持主流模型(如Llama3.1),但英伟达的GPU支持的深度学习框架和模型范围更广。对于已经深度集成在英伟达生态系统中的用户,Cerebras可能在模型支持的广度和灵活性方面略显不足。
来源:CerebrasSystems官网










评论